The Context Tax: Why Your Long-Running AI Agent Gets Expensive — and the One Pattern That Fixes It
A one-shot chatbot call pays for its context once. Ask a question, get an answer, done — whatever you pasted in gets billed a single time. A long-running agent doesn't work that way. It re-pays for its entire context on every turn. So a fat payload pulled in early isn't a one-time cost — it's a tax on every step for the rest of the session.
Most people's cost intuition is the one-shot model. For agents, that intuition is quietly wrong, and it's an easy way to burn a lot of money and a fair amount of electricity without noticing.
The one-shot mental model, and why it fails for agents
Every call to a language model is billed on input tokens plus output tokens. In a single chatbot exchange, "input" means the prompt you typed. Simple, bounded, over when it's over.
An agent isn't one exchange — it's a running conversation. Its "input" on turn 50 is the entire transcript so far: every tool call, every file it read, every result it got back. Nothing falls out of that context automatically. Whatever entered the conversation on turn 3 is still sitting there getting re-sent, and re-billed, on turn 50, unless something actively compacts or clears it.
That's the whole mechanism. It sounds obvious once stated. It's also very easy to forget while you're heads-down building, because nothing fails when you forget it — the agent just gets slower and more expensive, gradually enough that it doesn't look like a bug.
The concrete story
Here's where we actually found it. Our orchestrator — a long-running agent that manages work across several tickets — checks in against Jira at every status update, to stay grounded in what's actually true rather than drifting on stale memory. Good practice. The problem was how it checked in.
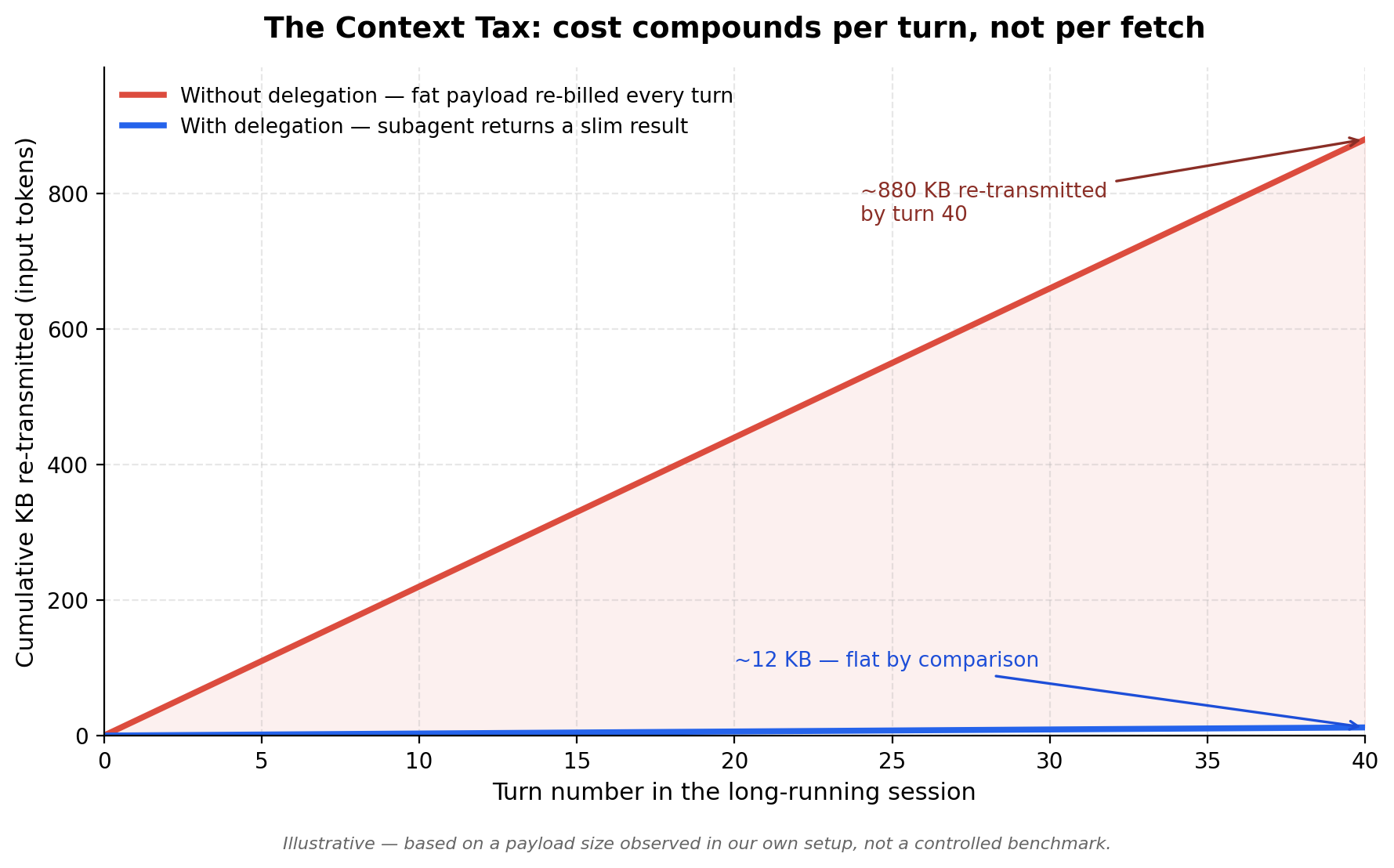
A single Jira query for five rows of tickets returned about 22 KB of JSON: full rich-text descriptions, avatar URLs, changelog metadata, all of it, because nothing was field-filtering the response down to what we actually needed (ticket key, status, assignee). In a one-shot call, 22 KB is nothing — you'd never notice it on a bill. In a long-lived agent that checks in every turn, that same 22 KB got re-read, and re-billed, at every single status check for the rest of the session. It turned into one of the largest line items in our token spend, not because any one call was expensive, but because the same call happened dozens of times.
(Worth being precise here: that 22 KB figure is a real number we observed in our own setup, not a controlled benchmark across Jira instances. Your mileage on any specific API will vary — the mechanism is the transferable part, not the exact byte count.)
The mechanism: payload × turns-remaining
The real cost of pulling something into a long-running agent's context isn't its size — it's its size multiplied by however many turns are left in the session. A 22 KB payload read once and forgotten costs 22 KB. The same payload sitting in context for 40 more turns costs roughly 40× that, because it's re-transmitted and re-processed by the model every single time.
And tokens aren't an abstract accounting unit — they're inference. Every token the model processes is a GPU doing work, drawing power, generating heat that a datacenter then spends water and electricity cooling. Re-read tokens are re-computed tokens: the same bytes, paid for in dollars and in energy, over and over, for no additional value the second time through.
The fix: "conclusion, not payload"
The fix isn't "don't fetch the data" — you need the data. The fix is deciding where the fetching happens. Instead of pulling the raw Jira response directly into the long-running agent's context, delegate the fetch to a subagent: a short-lived worker that does the heavy read, does whatever processing is needed, and returns only the conclusion.
In our case, that meant a subagent that hits the Jira API, gets the full 22 KB response, and hands back a few hundred bytes of slim rows — key, status, assignee, nothing else. The 22 KB payload lives and dies entirely inside the subagent's throwaway context. The persistent orchestrator never sees it; it only ever sees the distillate. The tax gets paid once, by a context that's about to be discarded anyway, instead of every turn by the context that has to carry everything to the end of the session.
Generalize it
Jira is one instance of a much more common shape: any time a long-running agent needs to touch something that's naturally big — a large file, a sweep through git log, a verbose API response, a scraped web page — that read belongs in a subagent, not in the main thread. Fetch heavy, return light.
There's a second benefit that's easy to miss: this is also a security firebreak. External content — a web page, a file from an untrusted source, an API response you don't fully control — never enters the main agent's context when it's routed through a subagent first. It can't carry an injected instruction into the conversation that's actually making decisions, because the main agent never reads it directly. Efficiency and safety turn out to be the same design decision here.
The honest trade-off
Delegation isn't free. Spinning up a subagent costs its own tokens and adds latency — there's a fixed overhead to handing work off and getting a result back. If a payload is small, or you're going to need the full detail repeatedly rather than a summary, delegating it is pure overhead with no payoff.
A rough heuristic: small and reused → keep it inline. Heavy and one-shot (or heavy and needed only as a summary) → delegate. Don't cargo-cult subagents into places they don't earn their keep — the goal is paying the tax fewer times, not avoiding it on principle.
Takeaways
- A one-shot call pays for context once; a long-running agent re-pays for it every turn.
- The real cost of a payload in a persistent context is its size times the turns remaining, not its size alone.
- Big, one-time reads belong in a subagent that returns a conclusion, not the raw payload.
- This pattern generalizes past Jira: big files, log sweeps, verbose APIs, scraped pages.
- It's also a security boundary — untrusted content that never enters the main context can't inject instructions into it.
- Delegate when the payload is heavy and one-shot; keep things inline when they're small and reused.
- Cost and carbon are the same lever: re-read tokens are re-spent power and cooling water, not just re-spent dollars.